Daybreak Natural Language Answers¶
Daybreak provides answers to your questions about data. Based on the idea that meaningful answers come from carefully cleaned and prepared datasets, Daybreak harnesses the power of the Aunsight data analytics platform to refresh an industry intelligent datamart nightly and serve it via a high-performance SQL database engine. While the SQL standard provides a reliable and widely-used technical interface, Daybreak natural language questions enable users of all backgrounds to get answers from their datamart by translating questions posed in natural language into the SQL query language used to obtain query results from the database.
How to Use It¶
Using natural language answers is incredibly simple. From the data builder start page, simply begin typing a question in the text input field and click "search."
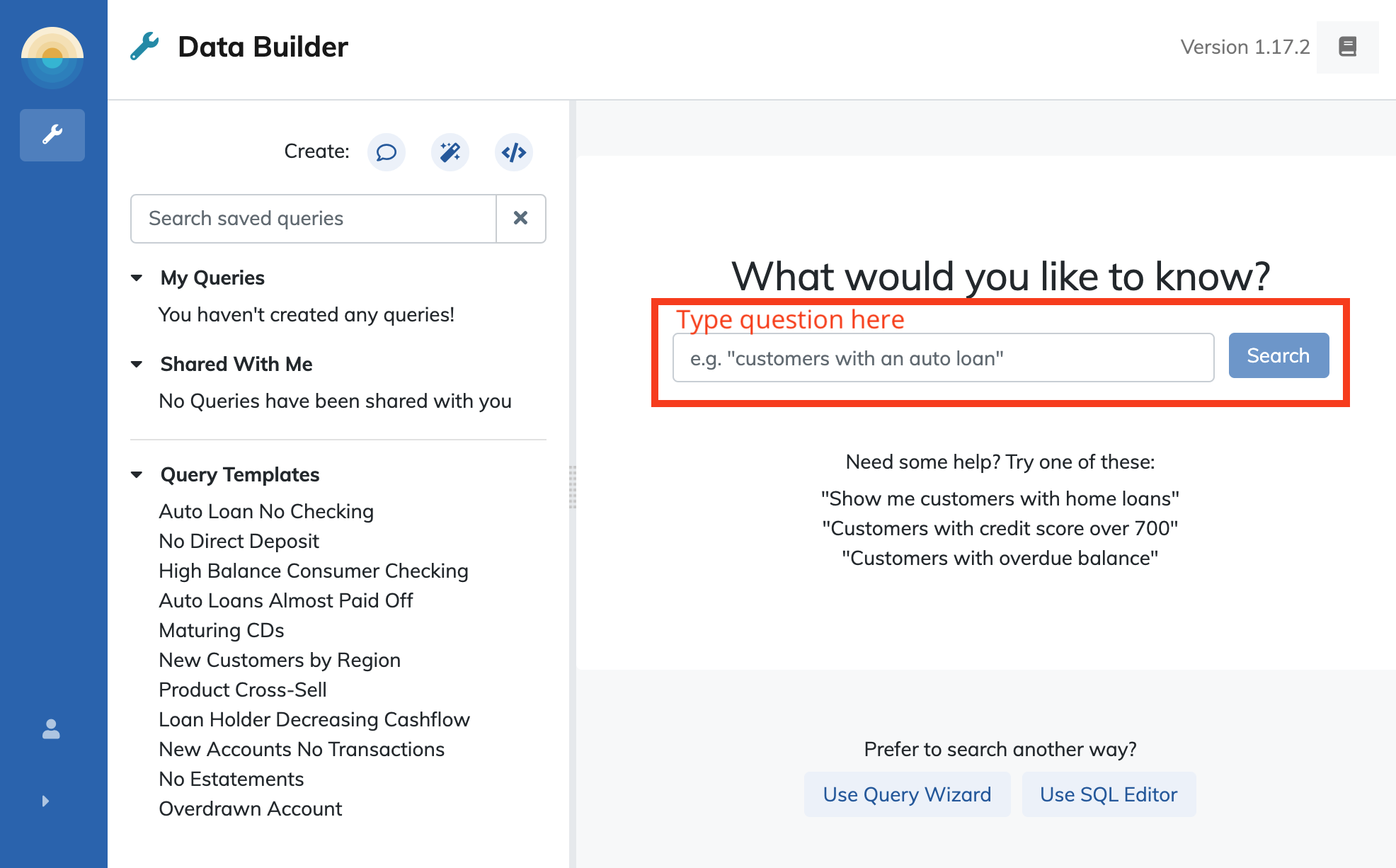
Daybreak will interpret your question and return structured query against the datamart and display those results in the query area.
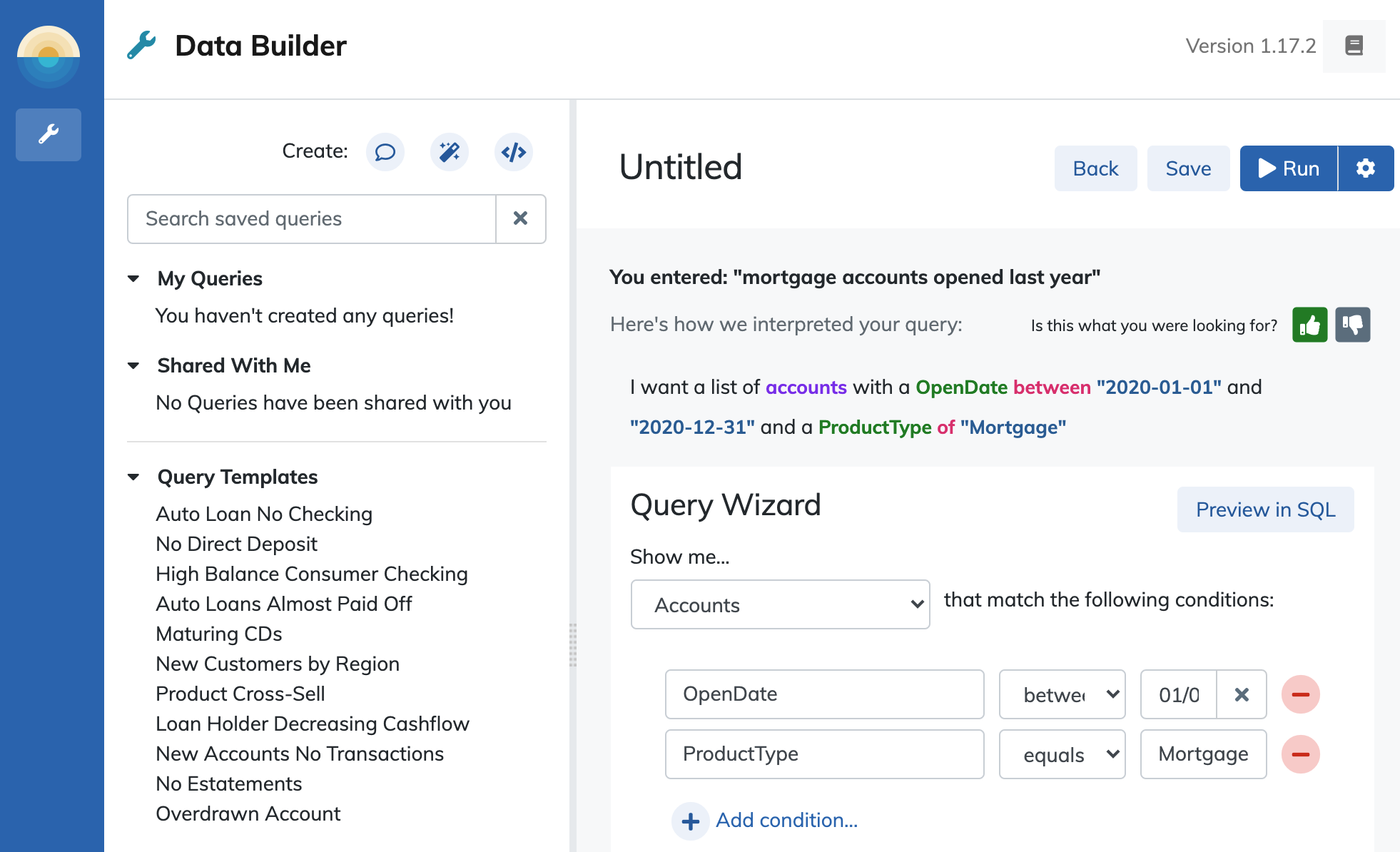
If the resulting query does not reflect your desired question or displays incorrect or incomplete results, you can modify the query manually in the query wizard area and even provide feedback to the Innovation Lab team to help improve the accuracy of the model. Alternately, you can return to the landing page by clicking back and try to rephrase your question to obtain better results.
If the results are correct, you can save the query. Click "Save" in the upper right hand side of the builder area and give your query a name and description then click "Submit" to add it to your saved queries (located in the "My Queries" section). Saved queries can be loaded and run at a later time or shared with other Daybreak users.
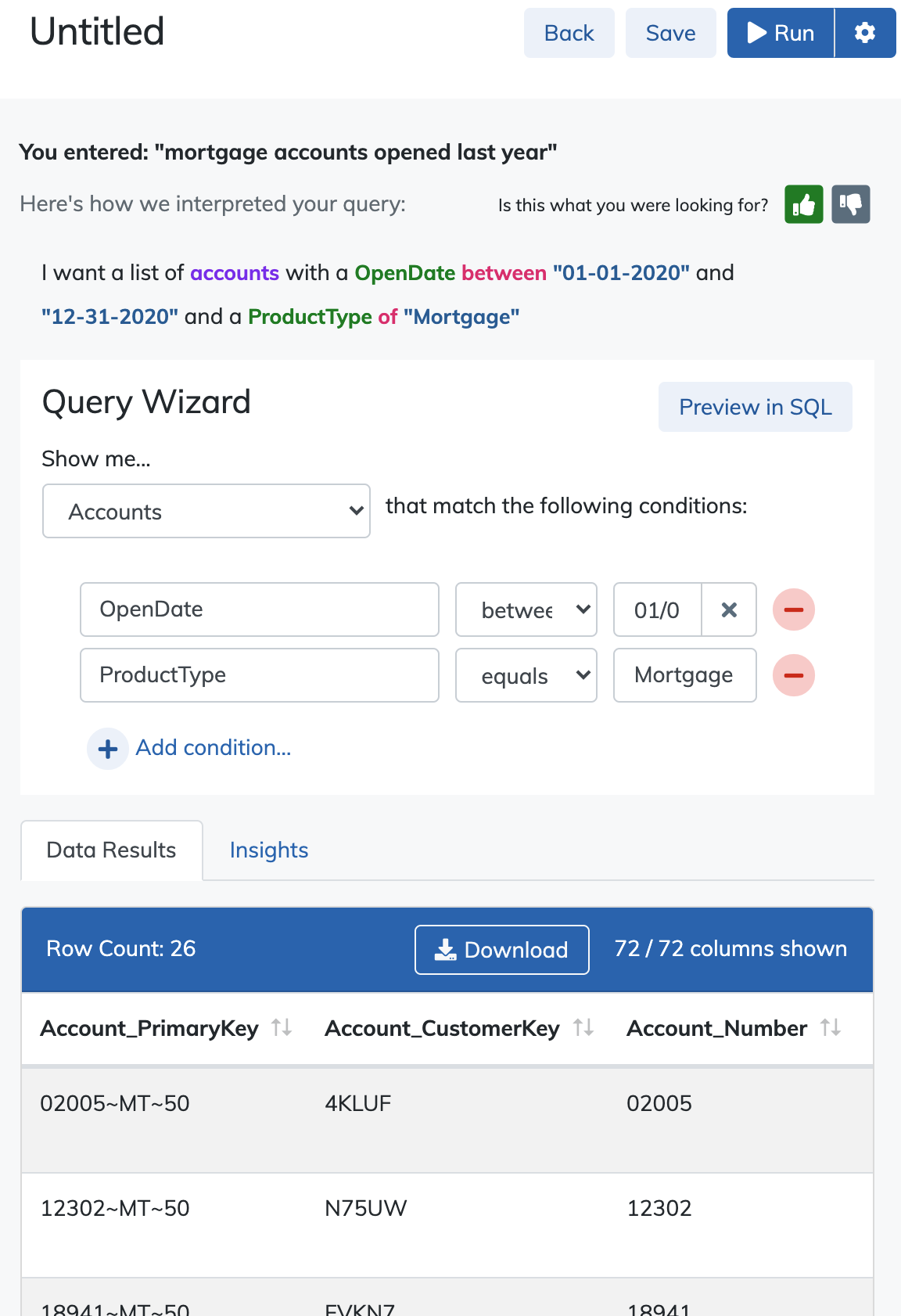
As soon as a query has been returned, Daybreak will immediately run the query and display the output in the results area. Users can page through the data to verify its accuracy and download the dataset in a delimited format (CSV, etc.) for additional analysis in another application or system (e.g. Microsoft Excel).
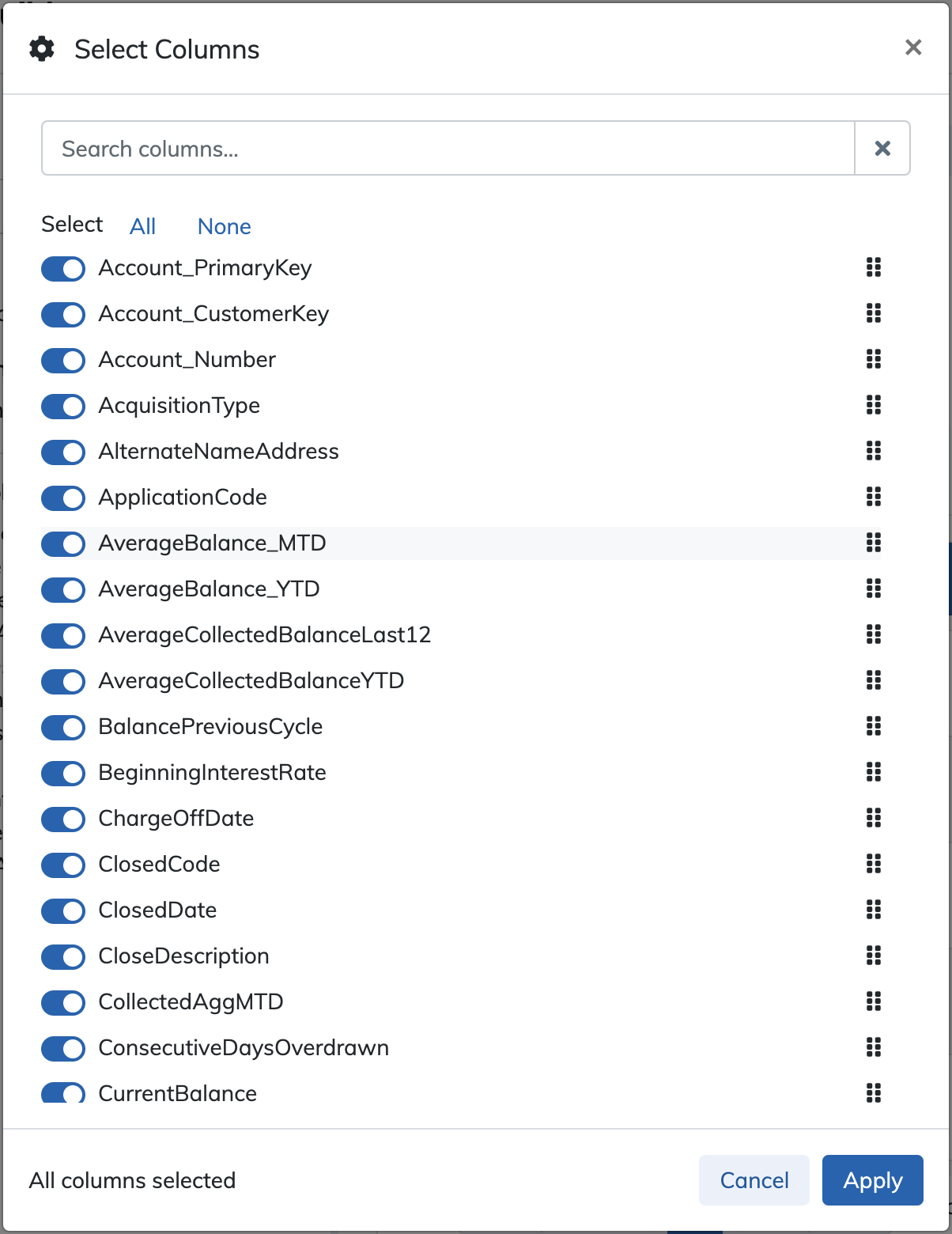
If you want to limit the output of the query by field, you can click the gear icon in the upper right corner to bring up a modal box to select the fields you want to have in the results. You can also re-arrange the order of the fields in the resulting dataset by dragging and dropping the waffle icon (![]() ) to the right of the field name to move that field up or down in the list of fields (by default, fields are sorted in their order in the datamart ../models/index.md schema). When you save a query, the selection and order of the fields in the result set will also be saved with that query.
) to the right of the field name to move that field up or down in the list of fields (by default, fields are sorted in their order in the datamart ../models/index.md schema). When you save a query, the selection and order of the fields in the result set will also be saved with that query.
At any time after making changes to a query, users can re-run the query by clicking the run button to have the data refreshed.
How it Works¶
Aunalytics NL2SQL is a proprietary machine learning technology built on top of the BERT deep learning model. Using a SQLOVA-based neural network, the Aunalytics Innovation Lab data scientists have trained the NL2SQL model to map natural language questions onto a training dataset of structured queries and identify field names from the Daybreak datamart.
The NL2SQL model's primary training data is a dataset of natural language phrases generated by Innovation Lab data scientists to represent common natural language questions within a domain specific context. For example, "I want a list of x customers with y attribute." The model is trained to understand different ways of asking for the same data, and also to disambiguate common phrases based on additional information provided in the question. Based on this initial structure, The model is then taught to identify keywords that appear in those question phrases and map those identifiers onto possible fields in the datamart. For example, in Daybreak for Financial Service, "mortage" and "home loan" are both represented in training data to enable the model to map these terms to the query condition WHERE ProductType == 'mortgage' in the Accounts table.
How It's Made¶
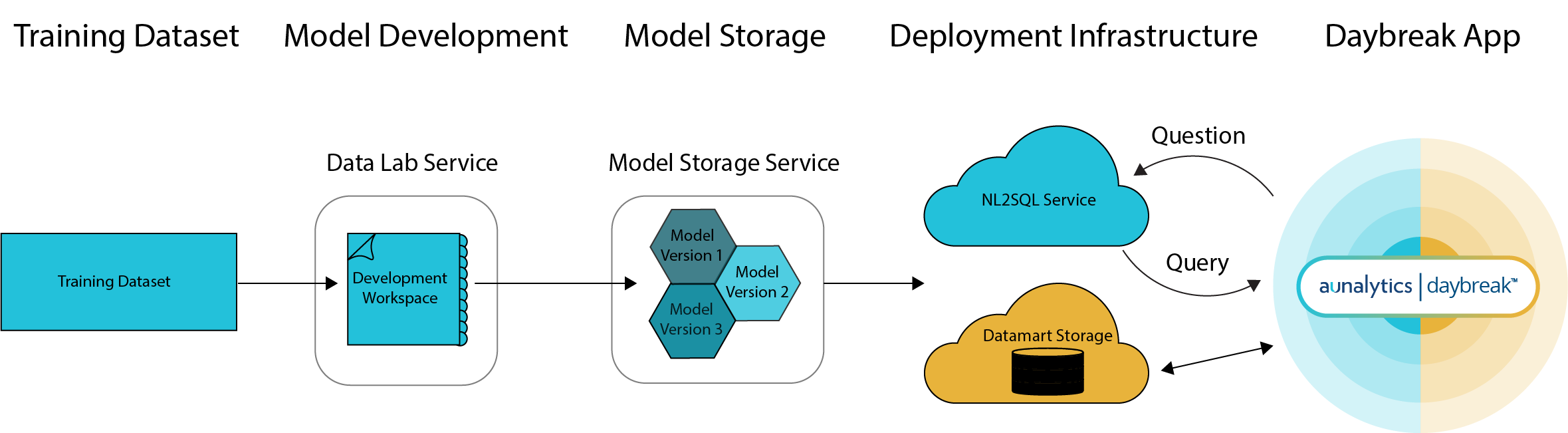
Model development begins with a training dataset specifically prepared for a target datamart. Example questions are gleaned from industry-specific phrases generated by analysts and combined to create a statistically representative set of questions by the dataset generator.
Aunalytics’ Innovation Lab data scientists create and maintain the training algorithms using the Data Lab tool developed for the Aunsight platform. Aunsight model workspaces provide the compute environment within which the processor-intensive task of training machine learning models takes place.
Trained model versions produced in the Data Lab workspace are serialized for storage in the Model Storage service, another component of the Aunsight platform.
Aunalytics' DevOps and Analytics Cloud teams provision and maintain the deployment infrastructure to ensure that natural language answers is secure, performant, and highly-available. The NL2SQL service runs within the the Aunsight analytics cloud where it can be scaled to respond to requests (questions) and provide responses (a structured query delivered by the requested NL2SQL model version) at any time and under any load. NL2SQL can process requests using one of any currently deployed models, enabling models to be trained and deployed for various datamarts serving different industries like finance, healthcare, or retail.
The Analytics Cloud team also manages the datamart storage engine used to process the queries submitted by the Daybreak app and return result datasets. This high-performance database engine serves requests from memory (RAM) for maximum speed and caches frequently requested queries for enhanced performance on frequently-requested queries involving complex SQL operations (e.g. JOIN statements).
Users interact seamlessly with this infrastructure through the Daybreak app's user interface. By simply typing in a question, a suggested query and the results of that query are delivered to the app within seconds, enabling users without any knowledge of database technology to get answers to their questions about data.
The NL2SQL development cycle is an ongoing process as new data, enhanced techniques, and user feedback enable greater accuracy. By providing feedback, users also play a critical role in enhancing the capabilities of this technology.
Limitations¶
Current development and testing efforts have identified a number of limitations in the model as it exists presently. The Innovation Lab development team is actively investigating these known issues and ways to augment the training datasets to improve results for the following cases:
- The model sometimes fails to find the correct table.
This most often results from missing or confused entity information. For example, asking "Give me a list of customers with no mortgage" will fail to produce results because the model attempts to find a "mortgage" field in the Customer table. In reality, mortgage-related fields are found in the Account table. In most cases, users can work around this by rephrasing the question to provide additional contextual information to the model. For example, "Give me a list of customers with no mortgage account" returns accurate results, because the word account helps the NL2SQL understand that the user is looking for data contained in the Account table.
- The model cannot return a query with more than one condition per field.
The model is currently limited in its ability to provide queries with more than one condition applied to a single field. For example, the question "checking accounts with a balance between 2500 and 10000" has two conditions on the same field (CurrentBalance >= 2500 and CurrentBalance <= 10000). Because the model cannot return more than one condition on the same field, it will return a query with just one of these conditions and ignore or misapply the second to another field.
For some data types (notably date fields) these expressions can be rephrased in a way that the model can interpret as a single condition. For example, while the model will fail to interpret "accounts opened after March 1, 2020 and before March 31, 2020", it will correctly interpret "accounts opened between March 1, 2020 and March 31, 2020."
- The model can't always identify an ambiguous field reference.
Certain words commonly found in questions can refer ambiguously to more than one field. For example, when a user asks for "customers from New Jersey" they most likely are interested in a customer's home state (Customer_State == 'NJ'). "New Jersey, however, is interpreted as the name of a city, and returns a query on the city field of the Customer table. In these instances, the correct result can be found by rephrasing the question in a more explicit way to suggest the appropriate table to find : "Customers from the state of New Jersy."
- The model cannot generate a range of dates to exclude results.
While users can easily generate ranges of dates to include in their queries, the model does not currently allow users to exclude a range of dates from the results. For example, the question "List all accounts not opened in 2020" cannot be interpreted by the model. The reason for this is because there is no equivalent construct in the structured query syntax used to train the model. Specifically, the structured query objects that enable the language model to map natural language questions onto SQL queries lacks a negative equivalent for the
date_betweenoperation. This means that although the language model has nothing to map negative date range questions onto at present, and therefore cannot be trained to understand them.
It is still possible for users to generate queries that would return these results by manually modifying the SQL code for a generated expression. For example, the question "List all accounts opened in 2020" generates the following expression:
I want a list of accounts with a OpenDate between "2020-01-01" and "2020-12-31"
The SQL code behind this expression is:
SELECT
*
FROM AU('Account') `root`
WHERE
(
`OpenDate` >= TO_DATE('2020-01-01', 'yyyy-MM-dd') AND
`OpenDate` <= TO_DATE('2020-12-31', 'yyyy-MM-dd')
)
Examining this query, the user with some knowledge of SQL can obtain the desired results by simply swapping the >= and <=.
Providing Feedback¶
Daybreak's natural language processing model undergoes regular re-training on new data prepared in response to reported problems. If you experience problems or receive incorrect results, you can help the Innovation Lab team improve the Daybreak natural language experience by reporting these problems using the feedback buttons to the right of your query results.

If your question returned satisfactory results, you can improve performance simply by indicating that the NL2SQL engine correctly interpreted your query by clicking the "thumbs up" icon.
If there was a problem with how NL2SQL interpreted your question, you can submit feedback that will be used to improve the training of subsequent model versions by clicking the "thumbs down" icon and providing a description of your experience in the "Tell us more" modal box.
When you submit feedback, your comments are recorded with your username, the text of the question originally submitted, and the query returned by the NL2SQL model. You do not need to supply this information in order to help us improve the NL2SQL model.
Information you provide that can help us improve the model should ideally include answers to the following questions:
-
Did the query result contain the fields you wanted? Sometimes the NL2SQL engine will not recognize certain fields and fail to add them to the query results. In these cases, it is helpful if you can provide the names of the fields which are missing so that these can be added to the training data used to generate the next model version.
-
Where any fields misidentified? Sometimes NL2SQL will misidentify certain field names, or return a field with a similar name from the wrong table. If a field or table has been misidentified in the query results, providing a list of the field(s) that were incorrectly selected followed by the the field(s) that should have been selected can help Innovation Lab data scientists create training datasets that properly disambiguate these fields.
-
Did the query return any data or was some data missing? Sometimes the NL2SQL engine will correctly identify the relevant fields, but the conditions in the query will be structured in a way that prevents the return of some or all of the desired data. Indicating whether data was missing from the query helps Innovation Lab understand if a problem exists in the query conditions so that they can improve the logic of query condition selection to prevent the exclusion of relevant data.